I apologize for bothering with my question on a Saturday afternoon, but something is not working out to solve one problem. My question is not urgent, but I ask for practical help if possible.
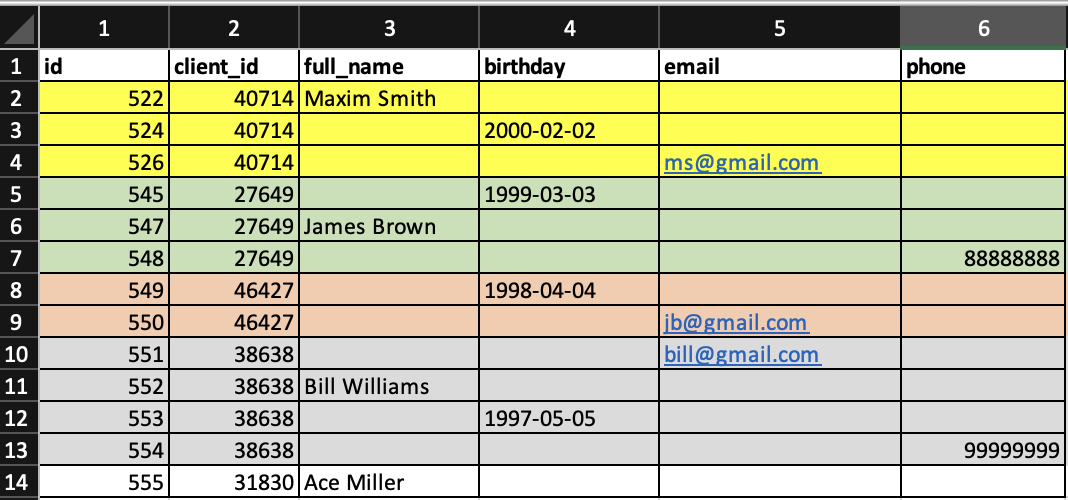
After converting the table in the “SPREAD” mode, the following file is obtained.
I need to fill in the missing fields. The key field is “client_id”.
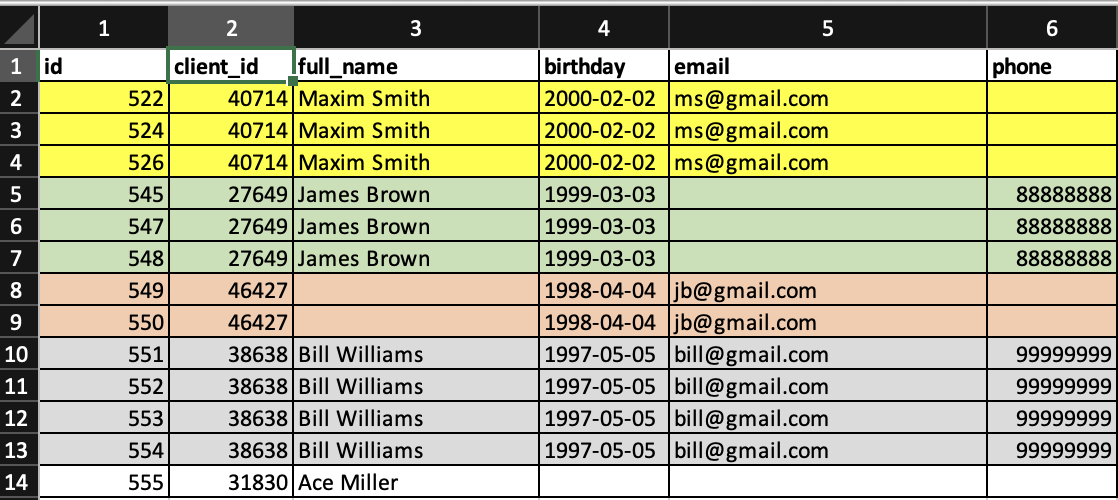
At the output, you need to get the file in the following form.
I will be grateful for the hints, since I am almost sure that there is a solution, but I can’t find it yet.
P.S. In the screenshots, I highlighted the entries with matching “client_id” with colors.
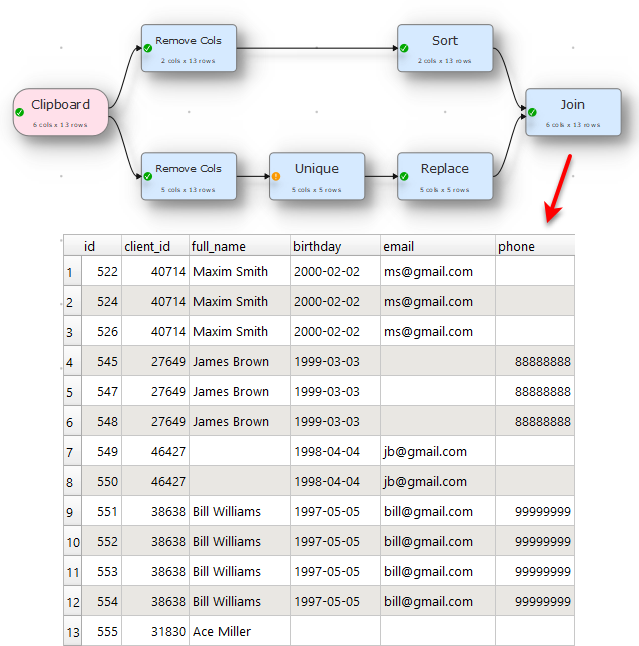
Thank you so much! The UNIQUE mode works just fine! I apologize for bothering you and for not being able to solve this problem myself.
I would like to take this opportunity to say that your program has saved me a lot of time and money. Previously, the programmer had to write or tell what I want to get as a result of file conversion. He recorded the task and wrote the necessary script. Now, thanks to EDT, I do almost everything myself. The result is faster and better.
Over the past year, I have been turning to programmers only with large files. Unfortunately, there is currently not enough processing in EDT with the number of rows of 10 million.
If you make it possible to process tables with 100 million records, then I will do everything myself, and I will fire the programmers)))
Admin
Of course you can post a review. For me, this is a real saving of time, nerves and money! I am very grateful to you for EDT!
That’s the thing, that memory does not end. I allocate 120+ GB of RAM for EDT and files up to ten million records are handled perfectly. There are not many columns (from 5 to 10).
But here is a file in which 50-70 million records are no longer loaded.
And this is sometimes very lacking. It remains only to hope that soon it will be possible to process them on EDT)))
@Admin , there is only first id, while the user wanted the id’s to be preserved as shown in the desired output screen shot.
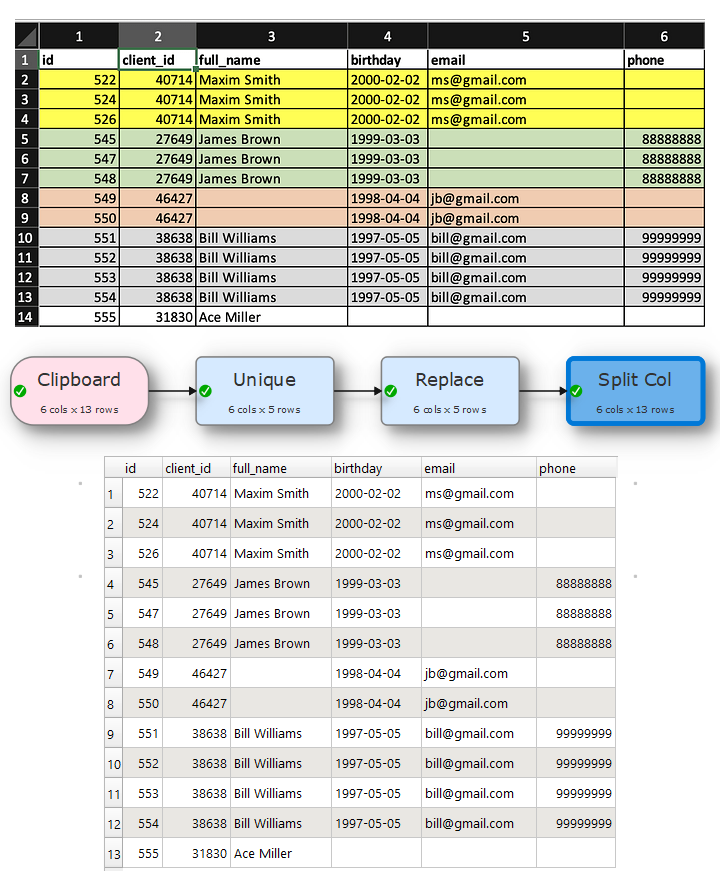
Learned something new in the process that you can leave concatenate field blank, though it highlight’s it with red, but still it let you continue, I did not know about it, as in other transforms it won’t let you continue if you don’t chose or provide value for the options.
It is just a suggestion, don’t know if you accept it or not, It would be great if you can make Fill and Unfill transform to have option to fill or unfill by using Column, like for example in this case
We could have set in the Fill transform column to be used for it’s range or group of records on client_id and chose the columns that need to be filled from single value in the chosen fields wherever it might by in the group or range of records.
So if we have something like that with Fill then above solution would have gone from six different transforms to just twol transform one Replace to cleanup the email and second Fill that makes it fast and consume less resources.
For Unfill in another thread I had to create blank row, to stop Unfill from removing the values in another set of records.
Example:
Area
Flow
Option
Condition
Sequence
Area A
Flow 3
Optional
Condition 10
1
Area A
Flow 3
Optional
Condition 8
2
Area A
Flow 3
Optional
Condition 7
3
Area B
Flow 2
Optional
Condition 2
1
Area B
Flow 2
Optional
Condition 5
2
Area C
Flow 1
Optional
Condition 1
1
Area C
Flow 1
Optional
Condition 2
2
Area C
Flow 1
Optional
Condition 3
3
Area C
Flow 2
Optional
Condition 2
1
Area C
Flow 2
Optional
Condition 5
2
In the above to make it more readable and remove repeating value Unfill in current state will remove Optional from all the records and will keep only for the first Record
Area
Flow
Option
Condition
Sequence
Area A
Flow 3
Optional
Condition 10
1
Condition 8
2
Condition 7
3
Condition 9
4
Condition 5
5
Area B
Flow 2
Condition 2
1
Condition 5
2
Condition 6
3
Condition 4
4
Area C
Flow 1
Condition 1
1
Condition 2
2
Condition 3
3
Area C
Flow 2
Condition 2
1
Condition 5
2
Condition 6
3
Condition 4
4
While it should be like this
Area
Flow
Option
Condition
Sequence
Area A
Flow 3
Optional
Condition 10
1
Condition 8
2
Condition 7
3
Condition 9
4
Condition 5
5
Area B
Flow 2
Optional
Condition 2
1
Condition 5
2
Condition 6
3
Condition 4
4
Area C
Flow 1
Optional
Condition 1
1
Condition 2
2
Condition 3
3
Area C
Flow 2
Optional
Condition 2
1
Condition 5
2
Condition 6
3
Condition 4
4
Also we could make option available in Slide transform for the group of records as well, that based on the group slide the values in the columns to the first record of the group for each column if they have value in any place within the group and slide that to the first record, after which we could use fill for example to fill up the group with same value.
Just few thoughts I had and thought why not put it out in open and either to be accepted or shot down.
I was actually thinking much the same thing. It would only work when Direction is set to Up or Down.
Perhaps if Direction is set to Up or Down it shows a For field with drop-down options All rows and Matching values for. If you select Matching values for you can choose a column.
Many thanks to dear @Admin and @Anonymous for participating in the proposed solutions!
For me, the solution to the problem was to use the UNIQUE function, since duplicates of information are immediately deleted.
I am very grateful to everyone, now I know the solution!
Once @Admin makes option available in Fill transform, to fill group of records with first non empty value based on a column that represents group of records, like in this example client_id and let us add columns that we want to be filled from the first non empty value (like when you want to filter you can choose which fields you want to filter on and choose conditions for filter) then it will reduce further to two transforms only i.e Fill and Replace in this case and if there was no need to remove additional value in the email field, then only one transform Fill.
That is from Six transforms to One transform will be quite a big change.
id client_id full_name
. . .
551 38638
552 38638 Bill Williams
553 38638
554 38638
555 31830 Ace Miller
Why not add third choice Both direction Up and Down as well, since now Filling or Un Filling using key. This will save extra step of sort or any other step to get data in correct order.