We were asked recently about how to extract the state part of dirty address data, like this:
632 Del Monte Ave. Powhatan, VIRGINIA 23139
733 Wood St. Passaic, NJ 07055
763 Mammoth Court Dunedin, fl
25 Randall Mill Street Santa Cruz CA
755 magnolia avenue norristown, pa 19401
9 S. Vine Ave. Pembroke Pines, Florida 33028
18 Snake Hill Street Tallahassee, FL 32303
179 Prince Ave., Billings, Montana 59101
8570 Arcadia Street, Sewell, NJ 08080
9335 Fordham Ave. Lebanon, PA 17042
78 Brickyard St West Hempstead, New York 11552
7272 Front St. Grove City OH 43123
(Note that these addresses are randomly generated, not real)
This is fairly straightforward using the new ‘contains’ match options in Easy Data Transform v2.
E.g. for Alabama we want to look if the address contains either ‘Alabama’ or ‘AL’ (case insensitive), looking for the longer term first. But we only want to match ‘Alabama’ or ‘AL’ as whole words - we don’t want to match the AL of Alexandria, VA. We can do this by using the regular expressions:
\bAlabama\b
\bAL\b
Where \b means word boundary, which could be the start or end of the address, whitespace or punctuation.
Here is a screenshot of the full solution:
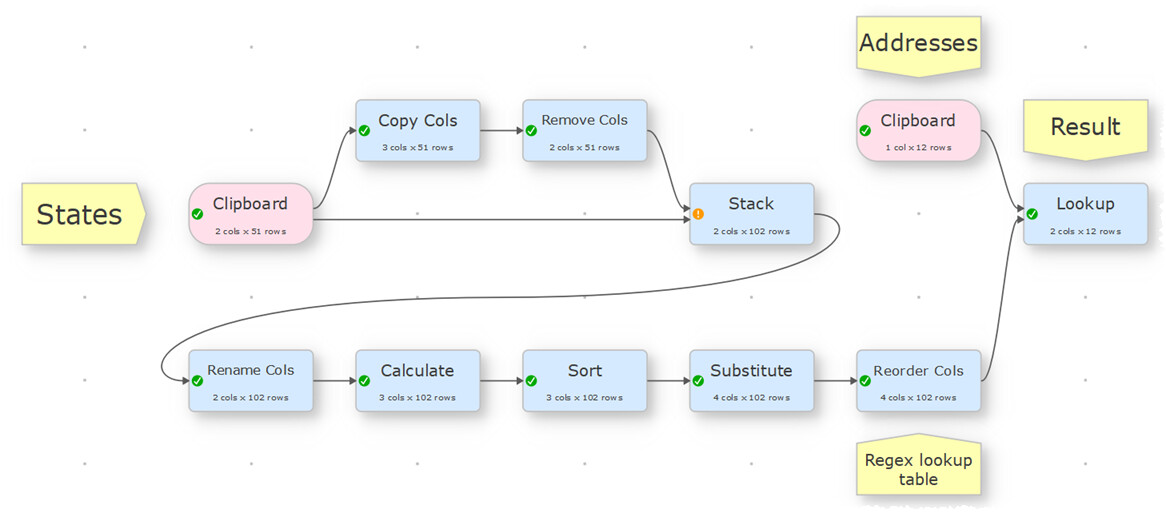
Here is the .transform file, you can load into Easy Data Transform.
states.transform (8.4 KB)
Most of the .transform is creating the lookup table, which is:
| State regex | State |
|---|---|
| \bDistrict of Columbia\b | District of Columbia |
| \bSouth Carolina\b | South Carolina |
| \bNorth Carolina\b | North Carolina |
| \bMassachusetts\b | Massachusetts |
| \bNew Hampshire\b | New Hampshire |
| \bWest Virginia\b | West Virginia |
| \bSouth Dakota\b | South Dakota |
| \bRhode Island\b | Rhode Island |
| \bPennsylvania\b | Pennsylvania |
| \bNorth Dakota\b | North Dakota |
| \bMississippi\b | Mississippi |
| \bConnecticut\b | Connecticut |
| \bWashington\b | Washington |
| \bCalifornia\b | California |
| \bNew Mexico\b | New Mexico |
| \bNew Jersey\b | New Jersey |
| \bTennessee\b | Tennessee |
| \bLouisiana\b | Louisiana |
| \bMinnesota\b | Minnesota |
| \bWisconsin\b | Wisconsin |
| \bDelaware\b | Delaware |
| \bIllinois\b | Illinois |
| \bKentucky\b | Kentucky |
| \bMaryland\b | Maryland |
| \bMichigan\b | Michigan |
| \bMissouri\b | Missouri |
| \bNebraska\b | Nebraska |
| \bNew York\b | New York |
| \bOklahoma\b | Oklahoma |
| \bVirginia\b | Virginia |
| \bArkansas\b | Arkansas |
| \bColorado\b | Colorado |
| \bMontana\b | Montana |
| \bIndiana\b | Indiana |
| \bAlabama\b | Alabama |
| \bGeorgia\b | Georgia |
| \bFlorida\b | Florida |
| \bArizona\b | Arizona |
| \bWyoming\b | Wyoming |
| \bVermont\b | Vermont |
| \bNevada\b | Nevada |
| \bOregon\b | Oregon |
| \bHawaii\b | Hawaii |
| \bAlaska\b | Alaska |
| \bKansas\b | Kansas |
| \bTexas\b | Texas |
| \bIdaho\b | Idaho |
| \bMaine\b | Maine |
| \bIowa\b | Iowa |
| \bOhio\b | Ohio |
| \bUtah\b | Utah |
| \bAL\b | Alabama |
| \bAK\b | Alaska |
| \bAZ\b | Arizona |
| \bAR\b | Arkansas |
| \bCA\b | California |
| \bCO\b | Colorado |
| \bCT\b | Connecticut |
| \bDE\b | Delaware |
| \bDC\b | District of Columbia |
| \bFL\b | Florida |
| \bGA\b | Georgia |
| \bHI\b | Hawaii |
| \bID\b | Idaho |
| \bIL\b | Illinois |
| \bIN\b | Indiana |
| \bIA\b | Iowa |
| \bKS\b | Kansas |
| \bKY\b | Kentucky |
| \bLA\b | Louisiana |
| \bME\b | Maine |
| \bMD\b | Maryland |
| \bMA\b | Massachusetts |
| \bMI\b | Michigan |
| \bMN\b | Minnesota |
| \bMS\b | Mississippi |
| \bMO\b | Missouri |
| \bMT\b | Montana |
| \bNE\b | Nebraska |
| \bNV\b | Nevada |
| \bNH\b | New Hampshire |
| \bNJ\b | New Jersey |
| \bNM\b | New Mexico |
| \bNY\b | New York |
| \bNC\b | North Carolina |
| \bND\b | North Dakota |
| \bOH\b | Ohio |
| \bOK\b | Oklahoma |
| \bOR\b | Oregon |
| \bPA\b | Pennsylvania |
| \bRI\b | Rhode Island |
| \bSC\b | South Carolina |
| \bSD\b | South Dakota |
| \bTN\b | Tennessee |
| \bTX\b | Texas |
| \bUT\b | Utah |
| \bVT\b | Vermont |
| \bVA\b | Virginia |
| \bWA\b | Washington |
| \bWV\b | West Virginia |
| \bWI\b | Wisconsin |
| \bWY\b | Wyoming |
(you could add some common misspellings to make this more comprehensive)
The key step is the Lookup:
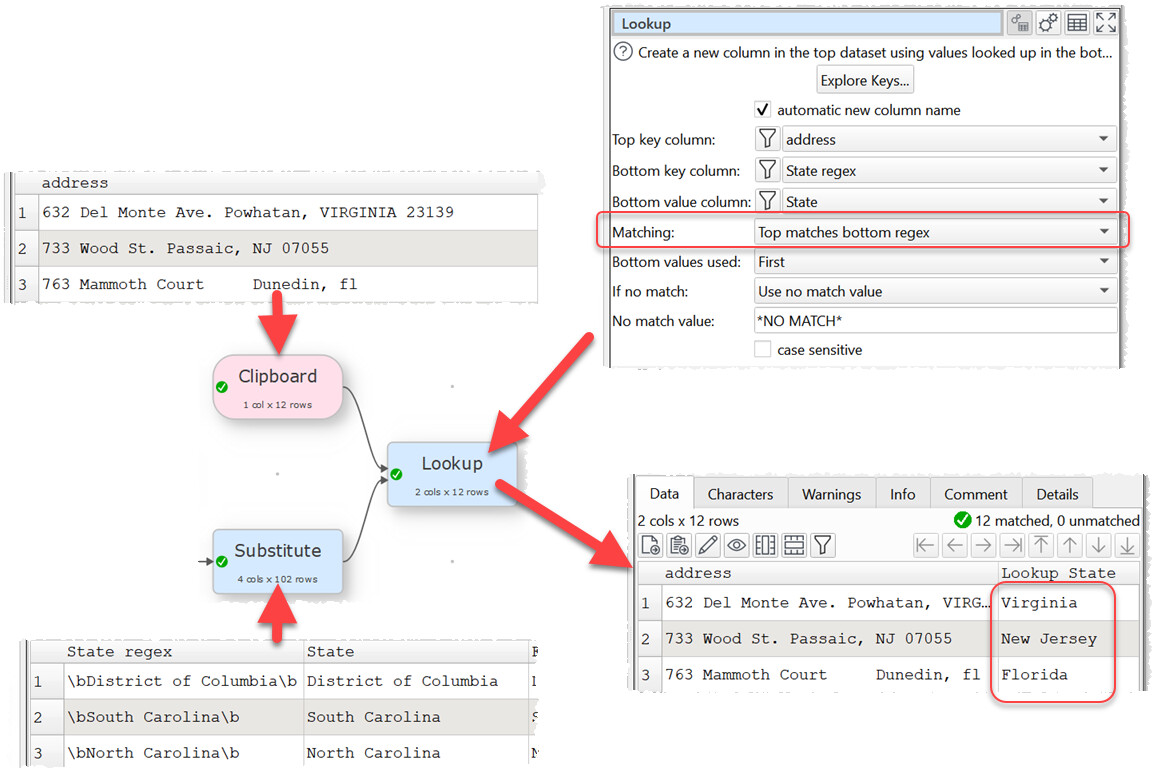
Any ‘misses’ are given value **NO MATCH**.
This approach was 100% successful for the small example dataset we used. But it is unlikely to be 100% accurate on real data, due to misspellings and issues such as:
Acme Co, Tampa, FL
Being classified as Colorado.
Or:
1 Alabama Av, Brooklyn, NY 11207, USA
Being classified as Alabama.
However, it should be accurate in the vast majority of cases. Also you could change Bottom values used to All in the Lookup and look for any addresses with multiple matches.

You could then Filter by rows containing commas or **NO MATCH**.