I have some irregular input data from which I want to extract two cells in each row. I can do this by writing a program, but was wondering whether anyone had quick suggestions about how it might be done efficiently in EDT.
The following is typical of the input (not an actual data sample but sufficient for the question): Problem input.csv (155 Bytes)
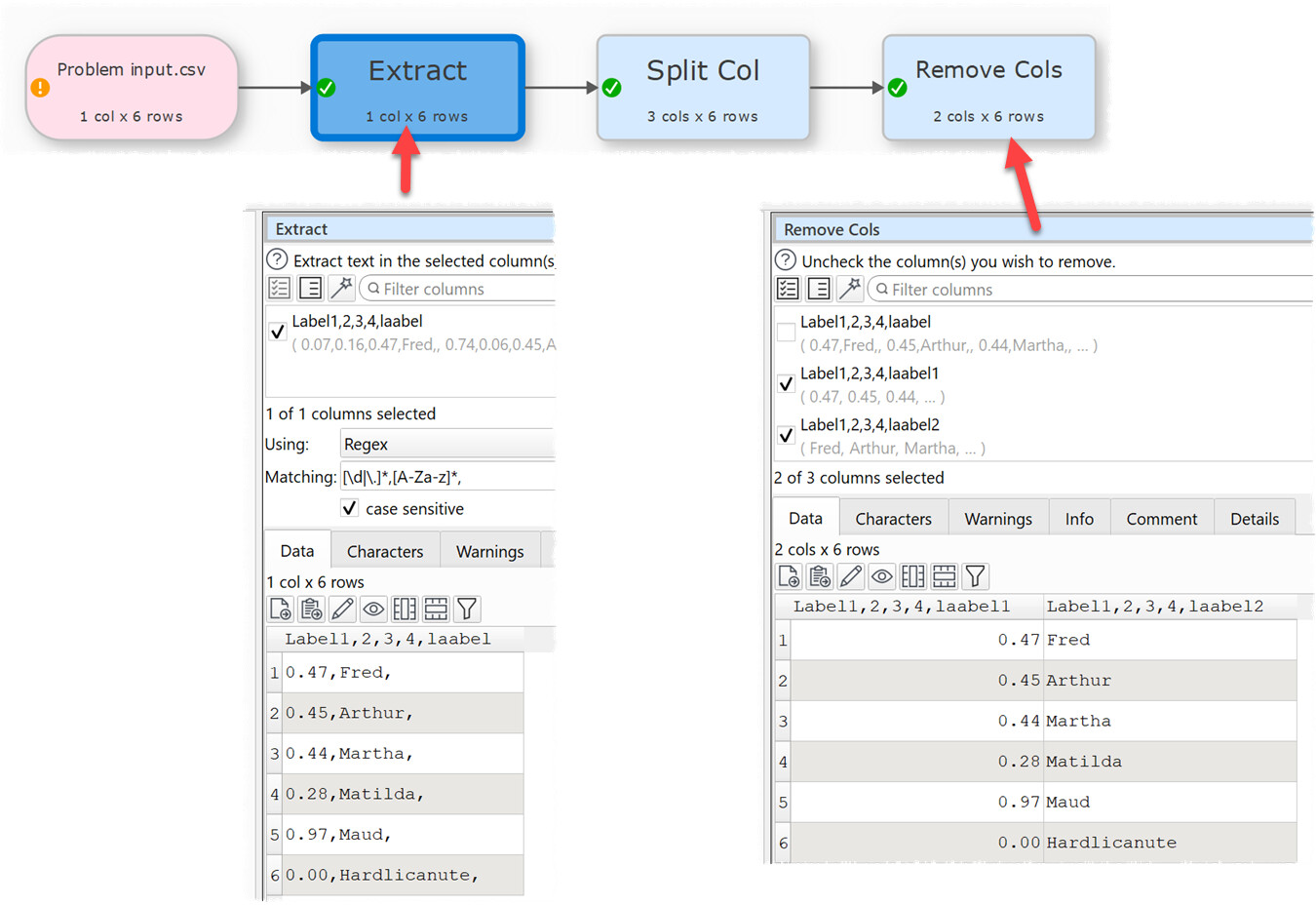
Note that the header names are unhelpful and columns not aligned so Schema does not work to organise it. The capture rule is that wherever there is text in a row – this will occur only in one cell per row – then capture the text and the numeric value in the column immediately prior, no other data. The text will never be in column 1. This would be output captured from the above: Desired output.csv (99 Bytes)
I did not spot anything in transforms to help. However, regex might? All numbers will be decimal between 0.00 and 0.99 and the text has only half a dozen possibilities.
Is there something fairly straightforward I have missed? Otherwise I will write a separate script.
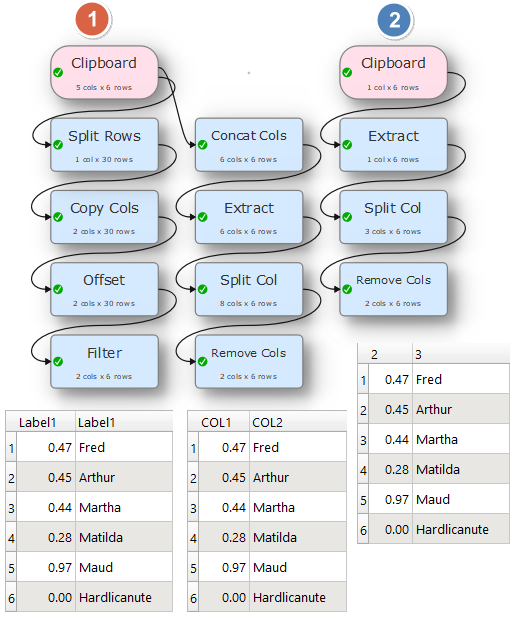
Here are few ways to do it, the first is, if you are reading from a csv file and the second one is, if reading it as a plain text, just like @Admin mentioned, I choose not to have header and skipped the first line.
Thank you @Admin and @Anonymous. While I will not have time to look into these solutions until late today, it seems clear that EDT will meet the task, and the forum remains ever helpful.
I understand those now thanks. Regex is key to the strings as I surmised, while the first Anonymous method shows how Split and Offset can solve this sort of problem, which fact is quite interesting.
An interesting simplification thank you Anonymous. Exploring (or seeing explored) different approaches to the same problem helps to broaden understanding of EDT’s capabilities.
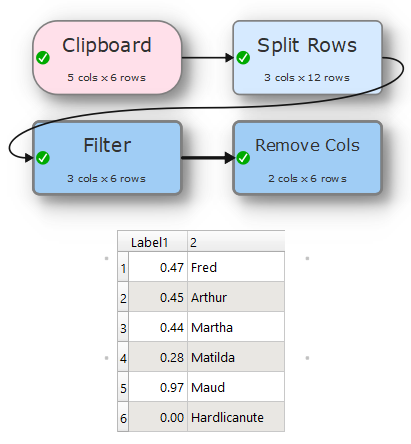
A constraint that was not known to you is that there are never any numbers in the column with text, so I can filter simply by removing ‘2 = empty’ rather than using regex.