Hi, i need to delete subsequent identical values in different rows in the same column, if value in other column is x
Thanks in advance
Hi, i need to delete subsequent identical values in different rows in the same column, if value in other column is x
Thanks in advance
Hi Antonia,
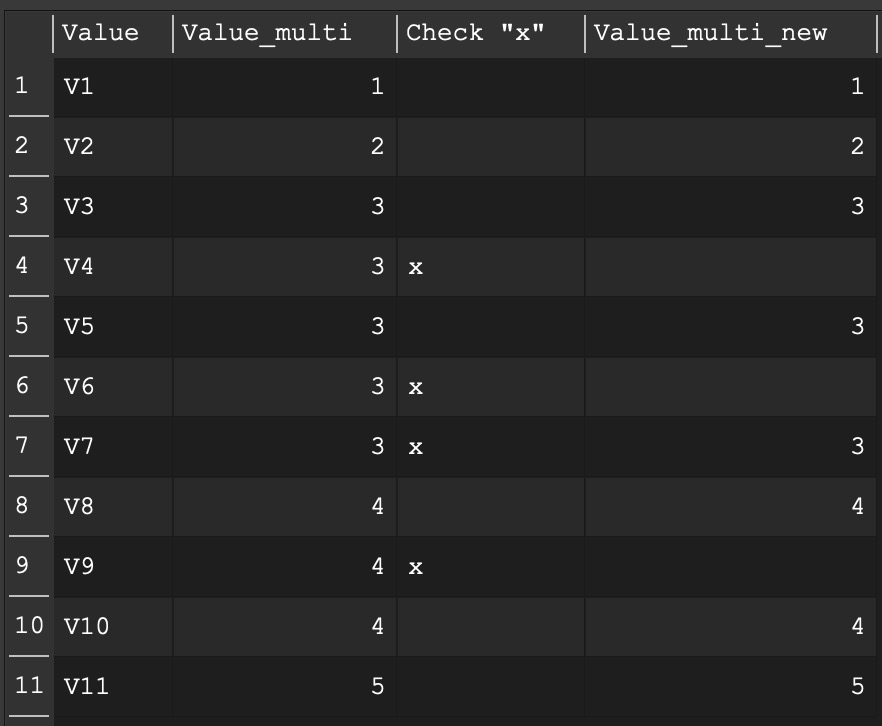
if I understand it right you want to remove duplicates in rows if a check value is “x”.
I created a table with a column “Value_multi” which have such duplicates. If it is duplicated in the next row and the “Check “x”” is “x” the new column “Value_multi_new” includes now an empty value. If you want to delete the rows you can set with the if transformation a special value and use this to filter (remove) such rows out.
I hope it gives an idea.
Antionia_remove_duplicates.transform (3.5 KB)
If @Olaf 's answer isn’t what you are looking for, then please can you supply a simple input and the correspoding output you want.
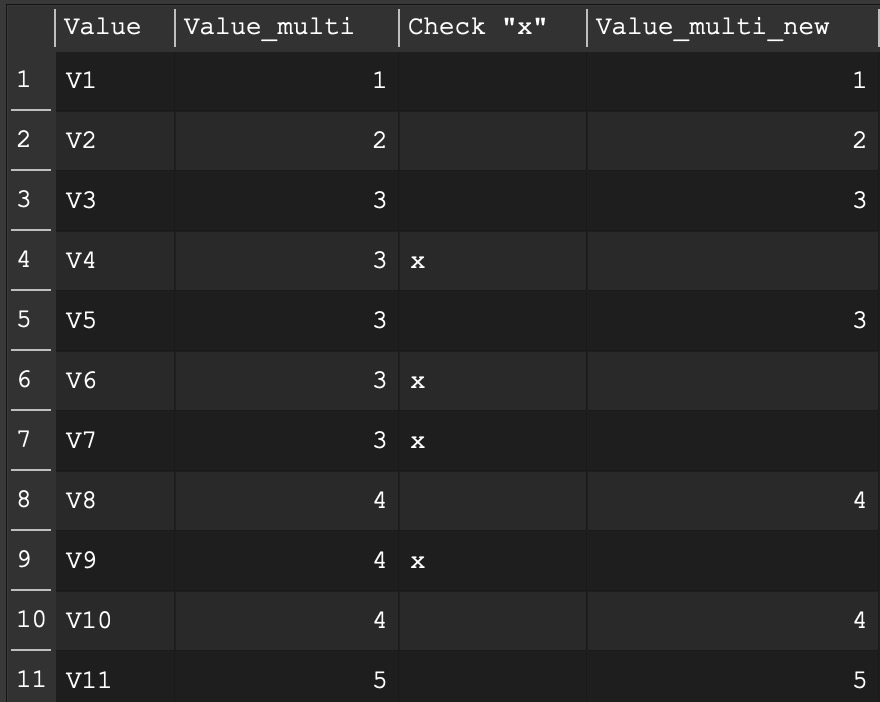
I had to correct the Direction in the Offset transformation and now it fits really to my understanding:
Antionia_remove_duplicates.transform (3.5 KB)
Since you did not provide which column is representing x and how you get that x, there is no way for us to provide you with the solution.
As @Admin said, it would be easy for us to provide solution if the input and expected out is provided.
Anyway, what I get is that you want to remove the duplicate rows and in the absence of how to identify x, here is my solution to remove the duplicates based on the data you have provided.
Transform file.
DeleteSubsequentDuplicateValues.transform (4.4 KB)
thanks a lot to everybody,
I want to delete all the identical values where there is no “abito” text in multiple columns.
tanks in advance for your invaluable support ![]()
We really need a simple example input and the expected output. A word description is too ambiguous.
Hi Olaf, thanks a lot for your support, I need to delete all the identical values in various columns deleting values in the rows where there is no abito txt in a certain column.
hope to have been clearer ![]()
Thanks in advance
Thanks ![]() I’ll prepare and provide you a sample.
I’ll prepare and provide you a sample.
I think I get it, Assume the column Check “x” as your column with the abitio txt. You need just to change in the if transformation the second argument form “=” to “!=” in the example I supported. And the “x” must be replaces by abitio txt.
Then I expect it will work as you want. If you are sure the abitio txt is only in the first occurrence then the infill transformation is the more efficient choice.
here is the sample
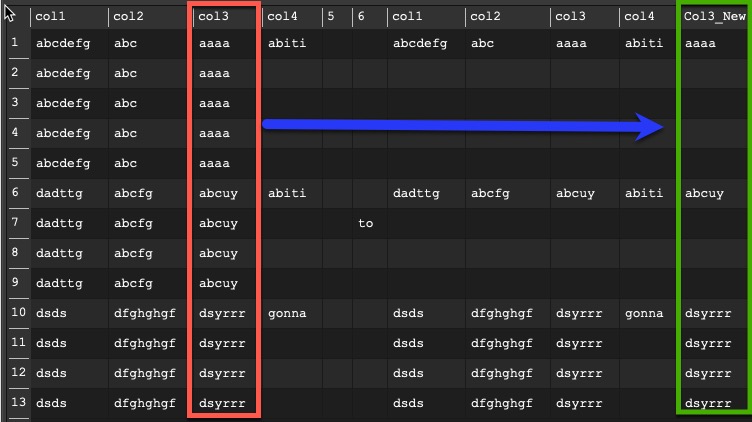
| col1 | col2 | col3 | col4 | col1 | col2 | col3 | col4 | ||
|---|---|---|---|---|---|---|---|---|---|
| abcdefg | abc | aaaa | abiti | abcdefg | abc | aaaa | abiti | ||
| abcdefg | abc | aaaa | |||||||
| abcdefg | abc | aaaa | |||||||
| abcdefg | abc | aaaa | |||||||
| abcdefg | abc | aaaa | |||||||
| dadttg | abcfg | abcuy | abiti | dadttg | abcfg | abcuy | abiti | ||
| dadttg | abcfg | abcuy | to | ||||||
| dadttg | abcfg | abcuy | |||||||
| dadttg | abcfg | abcuy | |||||||
| dsds | dfghghgf | dsyrrr | abiti | dsds | dfghghgf | dsyrrr | abiti | ||
| dsds | dfghghgf | dsyrrr | |||||||
| dsds | dfghghgf | dsyrrr | |||||||
| dsds | dfghghgf | dsyrrr |
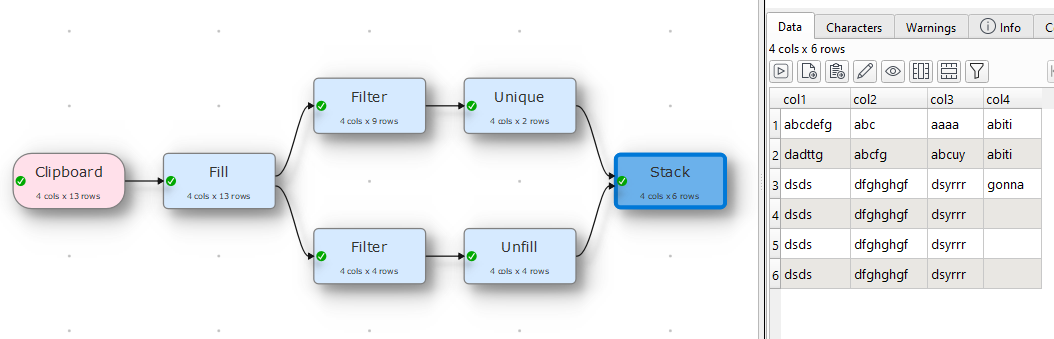
This look, like the abiti txt is every time in the first line, so use unfill and select the column where the values shall be removed.
Otherwise adapt the example I provided to the columns you need.
If you want to delete the rows with the duplicates you can add a filter and keep only columns where after the infill a value exists.
Thanks Olaf, that’s working quite well, but it also deletes duplicates where “abito” is not present.
Is there a way to execute a more granular and precise deletion?
but it also deletes duplicates where “abito” is not present
The example followed your first request, remove the value where no abito txt is … I struggle, for me your two remarks are contradicting
If it doesn’t fit 100% play with the condition in the if transformation
[quote=“Olaf, post:14, topic:1118”]
but it also deletes duplicates where “abito” is not present
![]() excuse me. i was saying that if there are multiple values repeating in a serie where abito is not the first of the serie but is not even present duplicates wil be deleted leaving the first row where “abito” is not present
excuse me. i was saying that if there are multiple values repeating in a serie where abito is not the first of the serie but is not even present duplicates wil be deleted leaving the first row where “abito” is not present ![]()
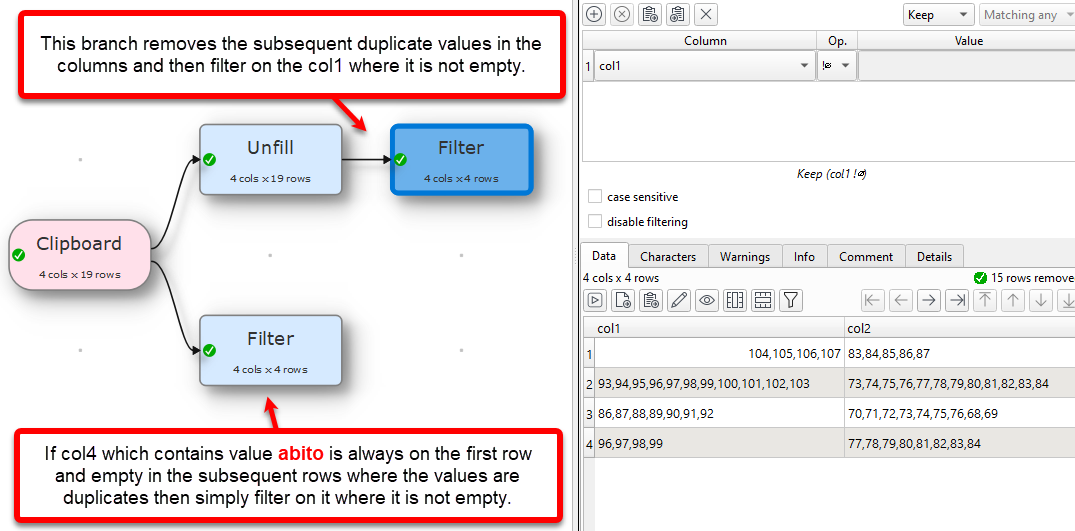
dedupe should work only when the first row of duplicates is containing “abito”, if duplicates check column does not contain “abito” the corresponding similar values should not be touched
| col1 | col2 | col3 | col4 | col1 | col2 | col3 | col4 | ||
|---|---|---|---|---|---|---|---|---|---|
| abcdefg | abc | aaaa | abiti | abcdefg | abc | aaaa | abiti | ||
| abcdefg | abc | aaaa | |||||||
| abcdefg | abc | aaaa | |||||||
| abcdefg | abc | aaaa | |||||||
| abcdefg | abc | aaaa | |||||||
| dadttg | abcfg | abcuy | abiti | dadttg | abcfg | abcuy | abiti | ||
| dadttg | abcfg | abcuy | to | ||||||
| dadttg | abcfg | abcuy | |||||||
| dadttg | abcfg | abcuy | |||||||
| dsds | dfghghgf | dsyrrr | gonna | dsds | dfghghgf | dsyrrr | gonna | ||
| dsds | dfghghgf | dsyrrr | dsds | dfghghgf | dsyrrr | ||||
| dsds | dfghghgf | dsyrrr | dsds | dfghghgf | dsyrrr | ||||
| dsds | dfghghgf | dsyrrr | dsds | dfghghgf | dsyrrr |
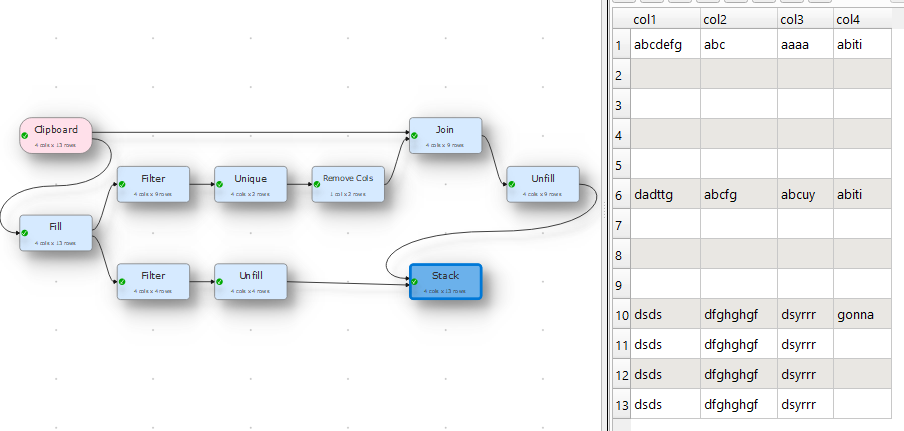
Here is your solution as per your Input and Output.
Transform file.
DeleteSubsequentDuplicateValues2.transform (3.8 KB)
@Anonymous was faster ![]()
But if you want to keep the rows and just delete some values, here is my solution.
thanks a lot Olaf.
I only have to adapt it to my data file now.
If you like to have empty lines, instead of removing them
Transform file.
DeleteSubsequentDuplicateValues3.transform (5.1 KB)
Thanks a lot! I have to understand all the process but is really astounding!