‘Schema drift’ is where the columns in an input change over time. E.g.:
new columns are added
existing columns are deleted
the column order changes
It can be a real nuisance for transformations that you run regularly.
In Easy Data Transform you can handle this using Stack. But this can be quite tedious to do.
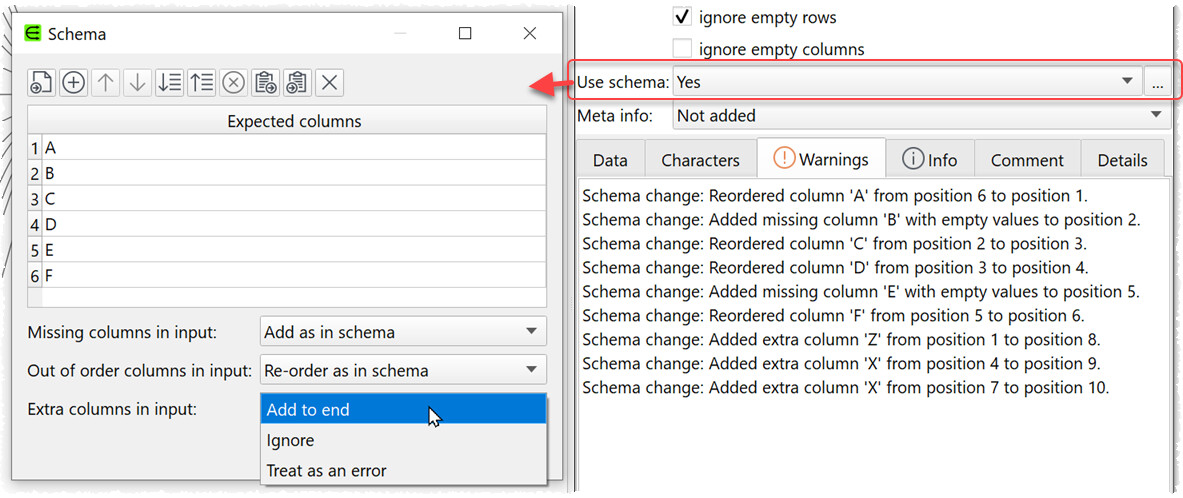
So we are adding a new Schema feature to inputs in v2. This gives you the option to store an ordered list of column names with each input and say what you want to do if the input does not match the schema.
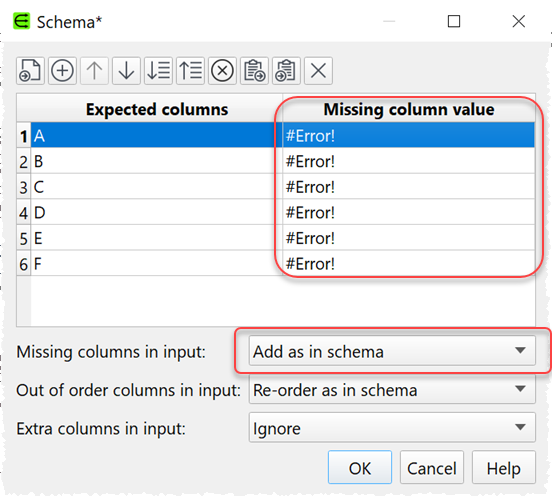
add missing columns (in the schema, but not in the input) with empty values
rearrange input columns into the same order as the schema
add or ignore extra columns (in the input, but not in the schema)
will be very helpful , but you will have to show the user the existing column order also to help
Give the option to enter ‘dummy’ column with ‘dummy’ value so in case a column is deleted , user can insert that too , to maintain integrity in calculation downstream.
As @Anonymous says, you can Stack columns by name. But the new schema versioning feature built into inputs should be more powerful and easier to use. Have you tried it?
yes, I know and tried it.
The new schema on import is so much more powerful and helpful! But as I said: I am more often working towards a given schema. The import schema does not help too much on this.