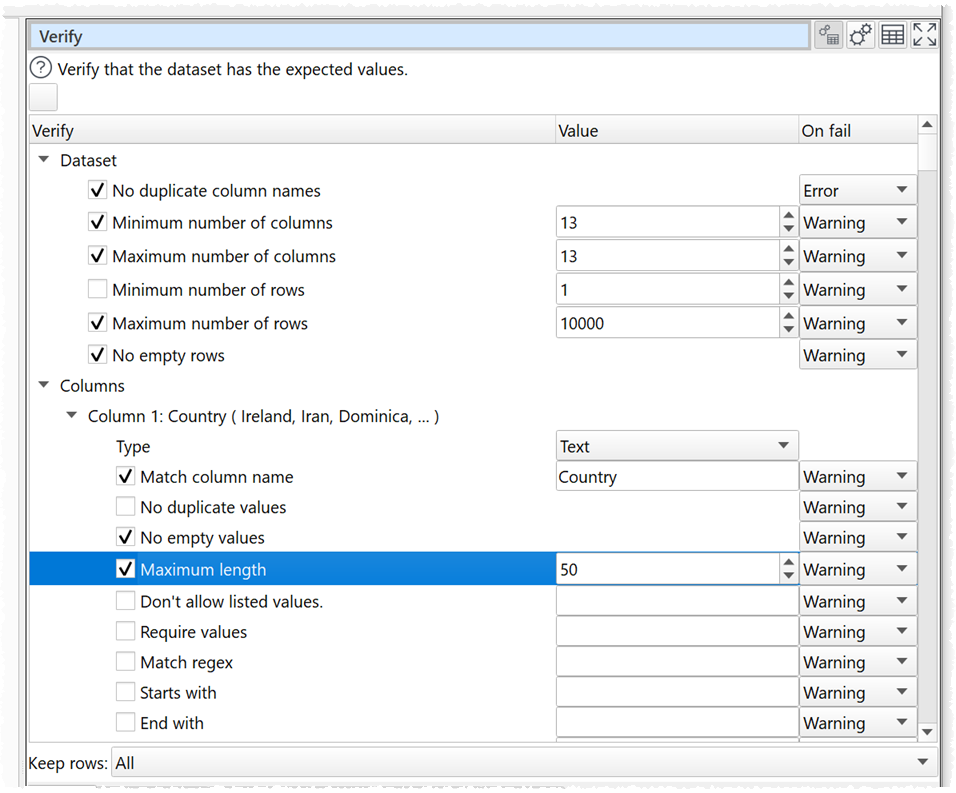
We are working on a new Verify transform for v2. It allows you to set powerful verification rules for the dataset and for each column. It is very much a work in progress, but here is a sneak peak:
You check whatever verification rules you want to apply.
Currently there are 6 dataset rules (shown above) and 40 columns rules. The column rules available depend on the type chosen for that column (text, integer, date etc).
If a rule fails you can output details to the Info tab, the Warnings tab or stop further processing and set the status to error.
You can choose to:
keep all rows
remove the rows with warning
keep only the rows with no warnings
Currently there are no checks between columns. For example, you can’t set a rule that the value in column A is always bigger than the corresponding column in column B. This is to keep things manageable. Also, you can already do these sorts of checks between columns with Compare and If transforms.
Questions:
What sort of data verification checks do you need to do, day to day?
Is there an agreed international standard for what constitutes a valid telephone number? A regex perhaps?
I’ll have to Google that to find out what is involved.
Is it something you have to do often?
We are currently planning to add various checks related to whitespace characters such as space, tab, line feed and carriage return. Were you thinking of other characters in addition to that?
Seperator Issue of Columns (CSV) - is the whole Dataset consistent? - for example a row has the seperator value- then u have in this row more columns and your dataset is destroyed (For example: check each row if you have the same amount of columns (syntax-check)
Yes, verifying EAN codes is nothing complicated.
As for special characters, I usually have to delete one of the non-printable ASCII symbols from the data ASCII Table -- Printable
I will have a think about that. We need to have a balance between having the verification rules people need and overwhelming them with too many options.
How about a Javascript verification rule? In other words, a Javascript snippet that returns true for data OK, false for problems. EDT would run through all the records, calling the javascript once per row.
That is the plan. However there could potentially be millions of fails. So we need to give some thought to how we present it. Perhaps a count of the number of each type of fail by column in the ‘Info’ or ‘Warnings’. Plus a way to drill down to find out more about the individual fails.
Hi Andy,
I’m excited about adding this to Easy Transform. I don’t know2 if this has any context for your users, but there is a good program with a developer’s kit for cleaning US addresses and formatting them to USPS standards. This includes writing/rewriting the address line, and adding the Plus4 number to addresses that it can recognize. It helps to clean them as well as verifying that there is an actual address at the location written to your data. Although most of your users won’t need the Plus 4 for mailing, it makes a dandy address verification indicator. It provides additional detailed information about each address, and even finds the proper city name from only the ZIP code and corrects “alias” city names to the preferred city name. Additional features include the exact county name and FIPS code, congressional district, area code, time zone, and daylight saving time status.
The USPS address database (700 MB) is updated every month so it’s easy to stay current. The supplied DLL has all the matching algorithms (per USPS standards), so all that is necessary is to feed it your address info and it will output it formatted and ready to go. If it can’t find a match, it will output an error code telling you what’s wrong with that location as written.
I know that there may be limited need for that kind of US info, but here just about all data appends are performed using address data to match and find records. (It also makes de-duping much more efficient!) It would be great if there was a part of ET that could make calls to the ZIPInfo-supplied DLL (available at: https://www.zipinfo.com/products/sdk/and update your US data. I know that the United Kingdom, Canada, Australia, etc. has similar address databases and perhaps has similar code available. Anyway, love using ET and am looking forward to your next version. Great job!
For now, we are only looking at ‘syntactic’ verification. E.g. ‘is this well-formed syntactically correct email’, not ‘does this email belong to someone’.