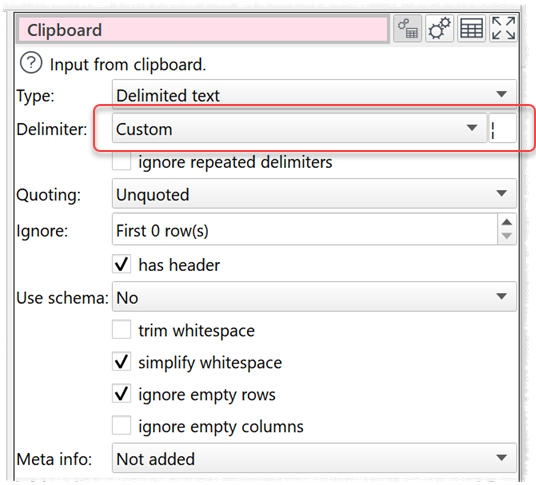
Ive got a CSV File with the delimiter for fields of ¶ and a valuelimiter of ¦
Currently i change the delimiter to ¶ and use a replace to remove the ¦, which is pita, if you have a lot of files to tackle. Since the fields might contain almost every character within text flow, there is no use for “ or ; or : .
So, how can i make life easier for me? I cannot change the value limiter, or am i mistaken? it only says quoted or unquoted or am i barking up the wrong tree?
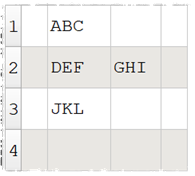
When I use the ¶ as delimiter, my data looks like this:
¦ABC¦
¦DEF¦GHI¦
¦JKL¦
So for each file I have to use a replace to get rid of them
Or I first import it in Open Office, where you can use field and value delimiter and the export it as xls to import, which makes it impossible to batch process…
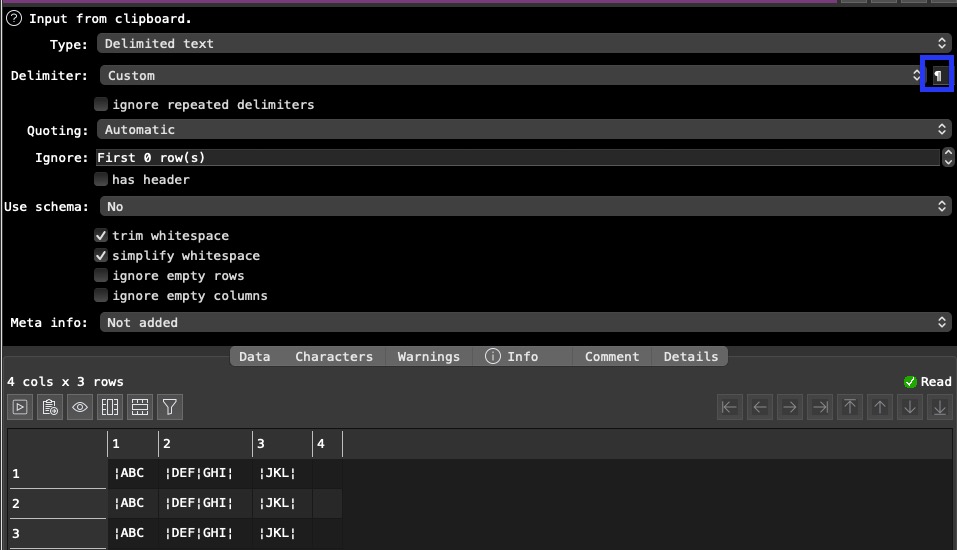
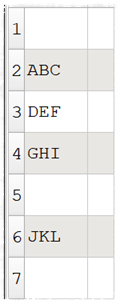
where is the issue? It copied pot row in a text editor in some rows. when I read it in and follow @Admin recommendation with the cisom delimiter and copy your ¶ sign in, I get a split in columns
See above in Open Office Calc. I can select “Seperated by” other and enter ¶ and enter ¦ as text delimiter. In EDT i can only enter the field delimiter, which is ¶. To get rid of the text delimiter (¦) I’d need a replace function, which i wanted to avoid. Since i can get full blown text with almost any character, those two are the only ones, which won’t be used in text fields, so i ended up with them as delimiters.
it assumes you don’t have linefeeds, carriage returns or delimiter characters in your data.
Note that currently Easy Data Transform supports custom field delimiters on input. But it doesn’t support custom record (row) delimiters on input. That is on the wishlist. So you have to use Split Col with Into = Rows instead.