I saw, that i can create a hash value of values in a column, i would like to have a hash value per row.
I am getting the same datasets continously and want to process only the rows, which have been changed. Since the source can’t add a date, the hash might do the trick, no?
So the idea might be, create an additional column to hold the hash for that row today.
Tomorrow do this with the new file and then compare based on hash column and only export those rows which have a nonidentical hash value.
If i use the column hash, i would have to compare 400 columns, that way i would only have one row to check, just because i might have up to 100k of rows…
Is this feasible or am i barking up the wrong tree?
It would be nice if you could give us some test data, to work with. Since you are at the moment role with Basic user, you might not be able to upload the file, you can use the following site that is recommended by Admin.
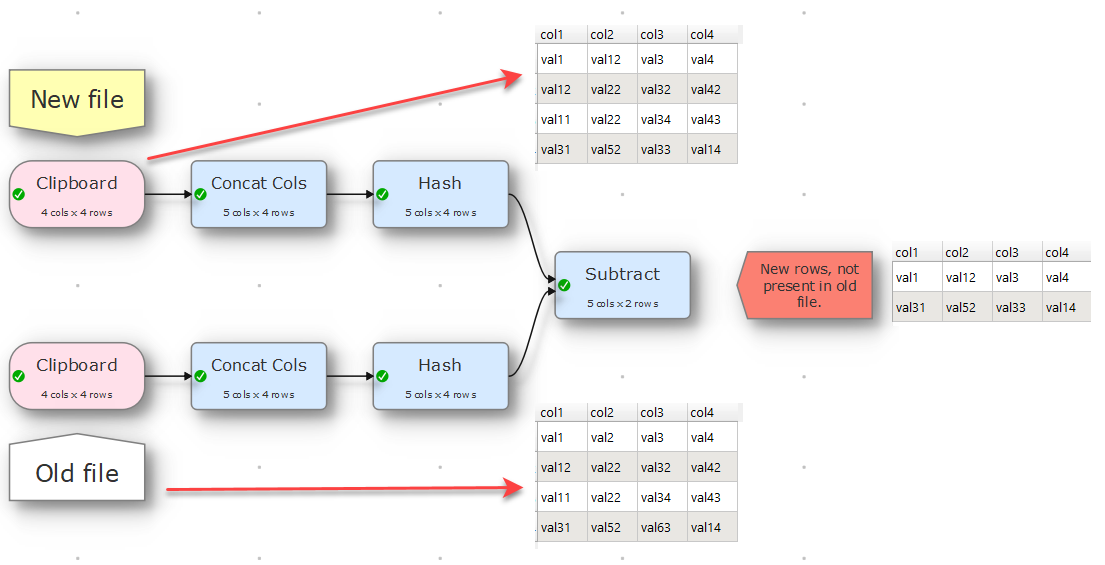
You could Concat Cols multiple columns into 1 and then calculate a hash using Hash.
But Subtract effectively does all that for you. It might be a bit slow on 100k rows x 400 columns. But probably still faster than doing your own hash.
So use Subtract to remove the rows from the new dataset that are in the old dataset. Once you have processed the new rows you can then Stack them with the old rows to create a new dataset.
Thanks, that one pushes me in the right direction. Concat with 300 or more columns might also be slow a bit.
The one from Anonymous worked out fine with demo data. On the other hand, just using Substract wouldn’t work out i fear, since the changes within the dataset might be hidden somewhere in one or more columns, therefore i would have to use the concat one.
I’d like to get around of the concat thing, if possible, so adding just a column with hash value would be brilliant I’ll stick to the approach with concat / hash / substract at this moment and check processing time in the future…
I believe that concat of all columns, hash and subtract is logically equivalent to doing subtract based on all columns, but the latter is more compact and likely to be faster.
Gotcha, i removed the Hash generation and just concat columns and then subtracted and now it will have the same result. Not generating hashes will of course speed up processing. Thanks for pointing out.