I often get files that I need to transform in order to load into a database table that doesn’t yet exist in my schema. It would be super helpful to have a “create DDL” function that lists out the column names and types, based on the final output file. Even if that’s not an option, a “list column names” function would at least do most of the work required.
Thanks
By DDL, do you mean something like this?
CREATE TABLE employee_table(
id int NOT NULL AUTO_INCREMENT,
name varchar(45) NOT NULL,
occupation varchar(35) NOT NULL,
age int NOT NULL,
PRIMARY KEY (id)
);
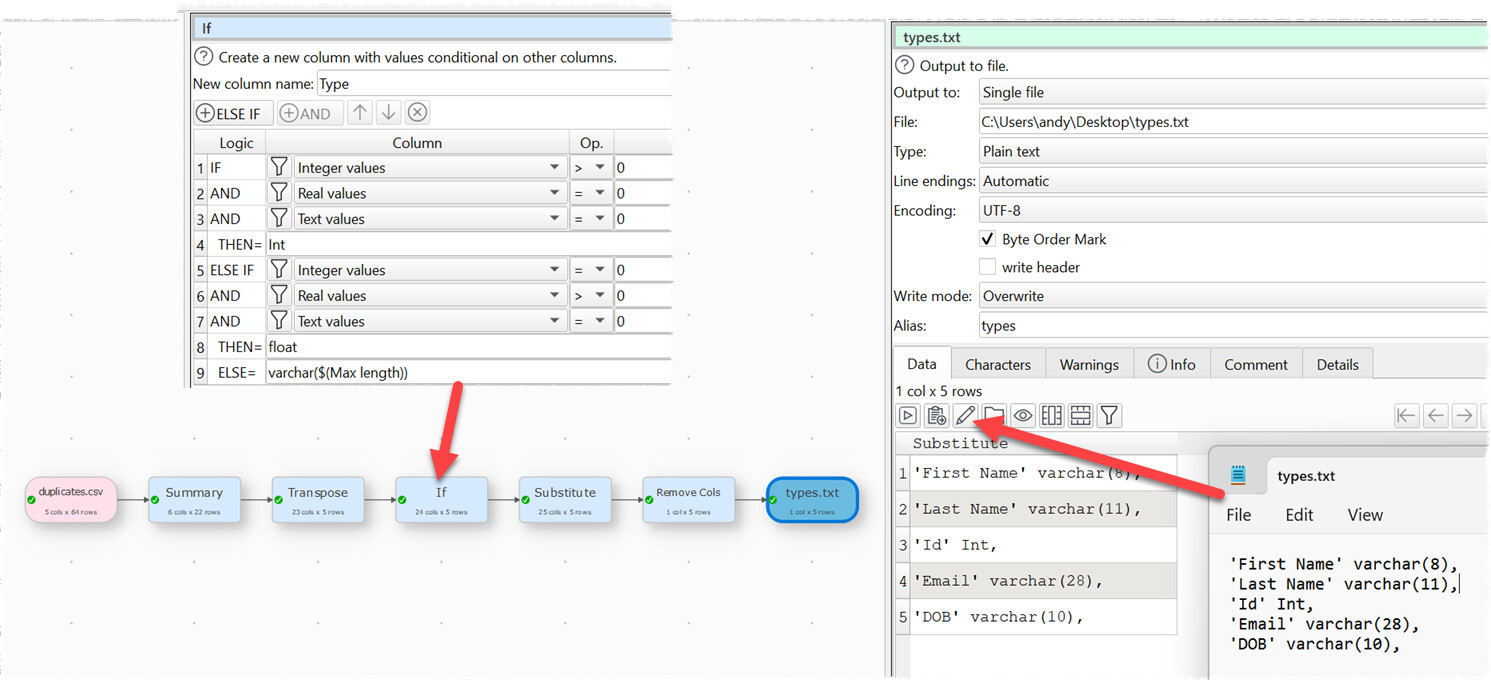
Some transforms infer column type. But we (deliberately) don’t have explicit column typing in Easy Data Transform. Even if we did, the types probably wouldn’t map directly onto SQL or other data types.
Note that you can output a text dataset with a list of columns, for any dataset.
column-summary.transform (3.7 KB)
You can then copy it or output it to a text file. Does that help?
Note also that the Summary transform has a lot of information about columns. You could probably Transpose and use some If transforms to output a likely type for each column.
We could possibly add an extra row to Summary with the inferred type.
Thanks for coming back to me.
Yes, totally appreciate the types wouldn’t match directly into SQL, but thought it would be a good starting point, which I could then edit afterwards.
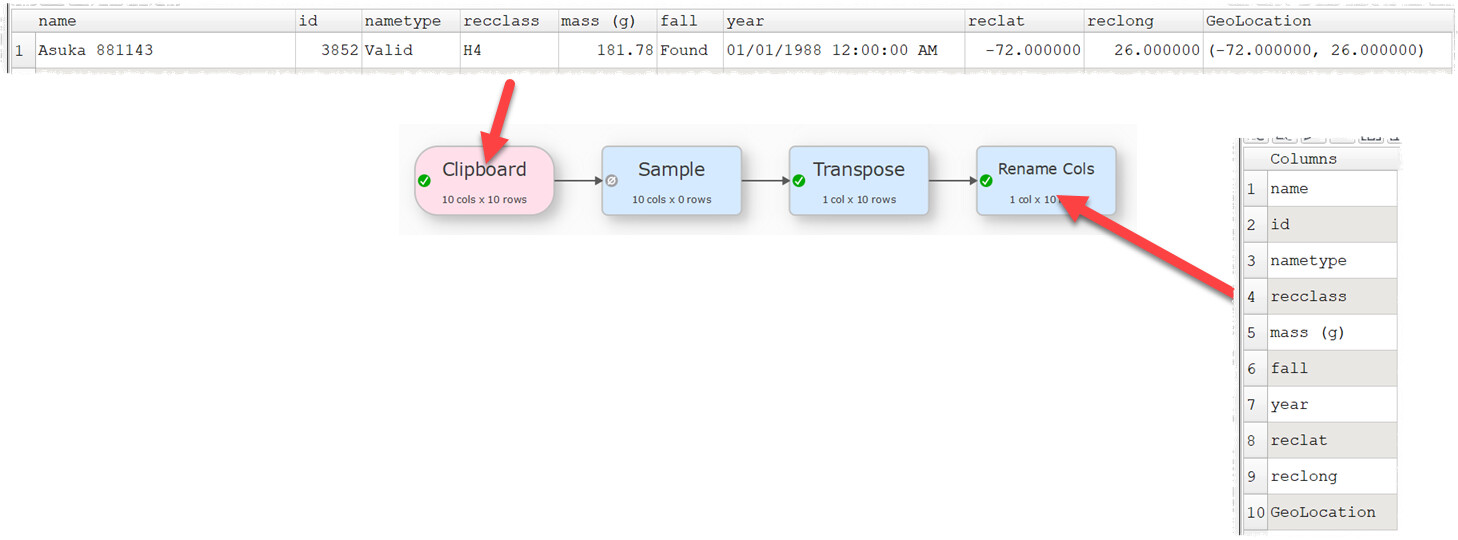
While I was hoping there was a single function that I can drag in to any of my transforms (me being lazy!), the sample/transpose/rename works best I think, even though I have to add the type afterwards. The summary/transpose option would only work with the inferred type, if the inferred type was the first row after the column names, so you could easily copy and paste it.
Thanks for your help.
1 Like