Well, we can use CLI, i found out, but, we can’t seem to manage to use batch function in my transformation via call through cli.
I will get each day approx. 60 csv files, which i will have to process, in some cases they are broken up in package_1, package_2 etc.
Instead of starting edt three or more times for each package, i’d like to setup batch processing and start it from my script. Any idea how to achieve it? Another option could be, to put the data from package 1 to package x into one export file, but the amount of packages may vary.
Thank you very much for pointing me in the right direction.
I am wondering, how to do that, since i never know, whether i will get 3 or 30 packages of a specific file. Unfortunately the dataprovider cannot write csv files larger than 384kb, so i end up with an unknown amount each day, being deltas, whereas no one can predict how many changes there are within a given export.
Would it be feasible to enable use of batch processing via command line at some point?
It depends.
-Do all the CSV files have the same column structure?
-Are you on Windows or Mac?
They both do the same thing. The batch processing is just a way to avoid writing a Windows/Mac script using the CLI. So I don’t really see much point in calling the batch processing feature from the CLI.
There are 9 different csv files from two ERP systems, which come with different attributes, but those with package1, package2 etc. come with the same structure but at some point with overlapping article ids (we are talking product data)
I’d like to call the batchprocess via script, because need to process all the data upfront before importing…
PS. So i would need to call the transformation for each package, instead of just reading each file in a folder one after the other without adding a line in the script for each file, where i don’t know, whether i get it or not.
Since i need to preprocess 30+ files in different steps, i wanted to keep the script smart and short…
I think all your are looking for is possible. I have a lot of repeating activities & reports I do, sometimes based on unknown number of input files scripted. You should go through the documentation Admin has posted. EDT even creates for you the complex arguments for scripts which you can copy out.
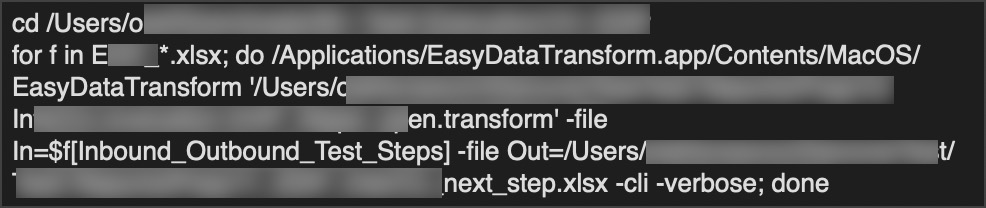
In this one, it changes to the folder with the data and then a loop is started for all files with a given pattern and joker, so you can use “package *.csv”. In my example for the files “f” even a dedicated tab in the Excel file is used.
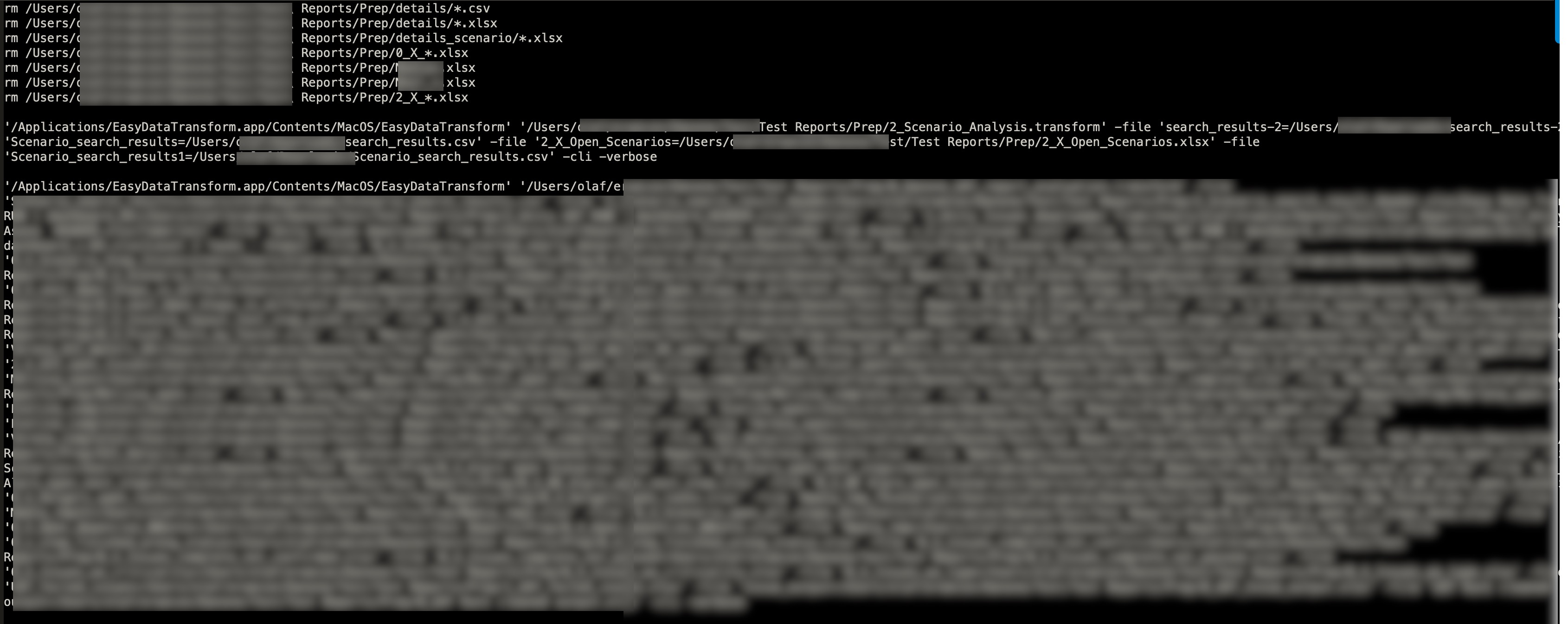
In this example a big number of output files are written (some hundred), but the amount is dependent on the data in the input files, therefore the script delete first the old output files before running two EDT scripts. As not all files might be overwritten.
Specially if output files are generated in Append mode you need to consider on remove or rename the files from run before, depending of your use case.
But the first time creating it needs some time, specially when building the loops.