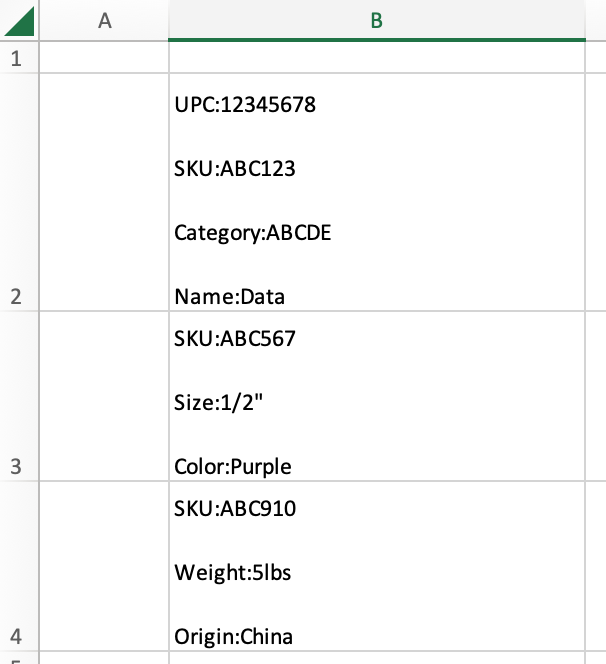
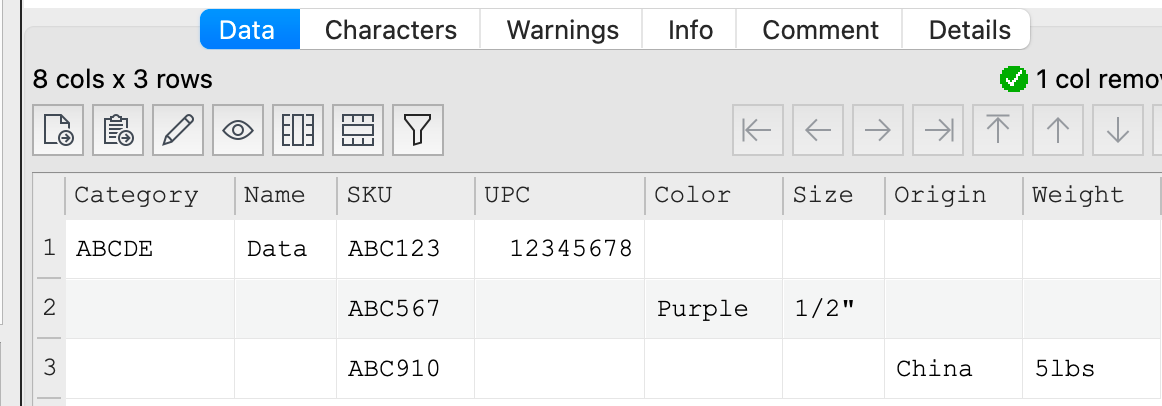
I have a files in which a single column’s record contains lots of data in it, which can I’d like to extract to columns that match the data as organized in the cell. The column headers UPC|SKU|Category|Color|Size|Origin already exist (all blank/empty). The cells for each record don’t follow the same content/order for all, so there are approximately 300 columns the data could go to.
The data in a cell is structured (with line breaks) as:
I see what you’re going for, as I had tried the split col and spread functions previously, but it’s not complying with me. The line breaks don’t seem to respond to regex the correct manner.