We are looking into making some significant improvements to Dedupe and Unique transforms. Including the option of fuzzy matching. If you are interested in trying an early version and sending feedback, please email us (subject: “dedupe testing”) at the usual address:
2 Likes
We load a lot of employee data where the employer will often times have duplicate “unique” IDs. its in quotes, because often people are listed 2x times in the data for various reasons. we have to do a lot of sorting and the de-dooping based on other data points within the data. not sure if thats what you are looking for, but happy to help if we can and have the time…
@patrick I will let you know when we have something to try.
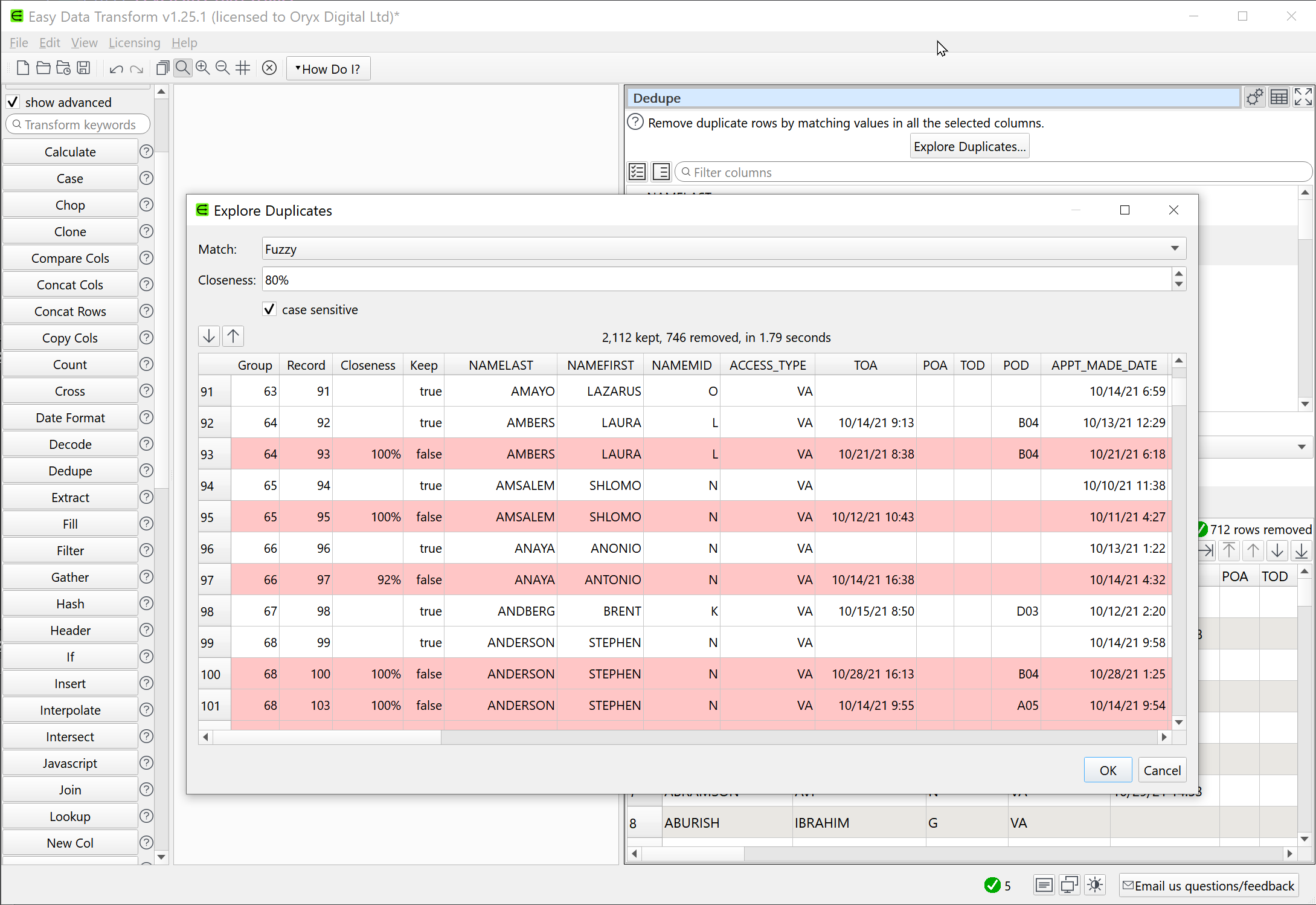
I can’t wait to test and use this new Fuzzy option.
Fuzzy matching of duplicates and the ability to view duplicates are now available.
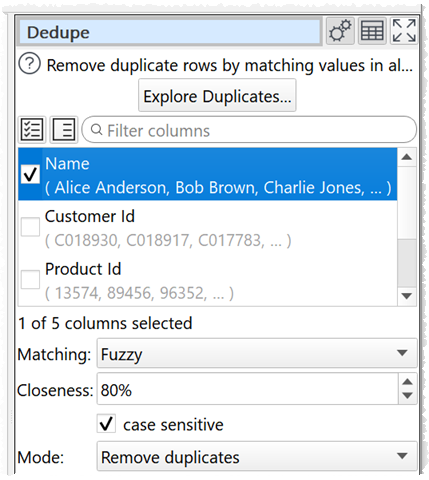
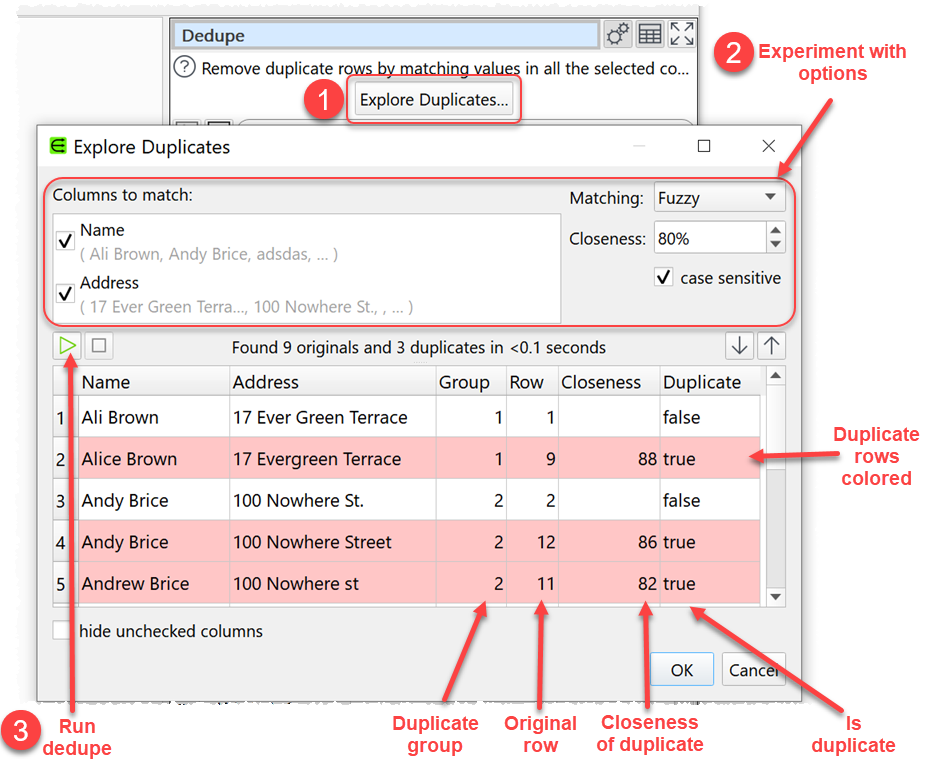
See sections 2 and 3 here:
(you may need to refresh the page)
Because of the way Easy Data Transform works you can’t manually select duplicates, but you can set the ‘Dedupe’ mode to ‘Add duplicate information’, export the dataset and do it manually in an editor.
Please try it and let us know what you think.