Indeed. But I am just anticipating that people will complain that it doesn’t remember the custom values entered for a different .transform file.
Did any people ever complaint, that the conditions they put in Replace transform or If transform or Filter transform or DateTime Format transform and such, is not present in their other transform?
So why should they complaint about this? that it is not present in their other transforms. Just like they put conditions back, they can put the same in here as well in different solutions.
1 Like
Thanks for the feedback.
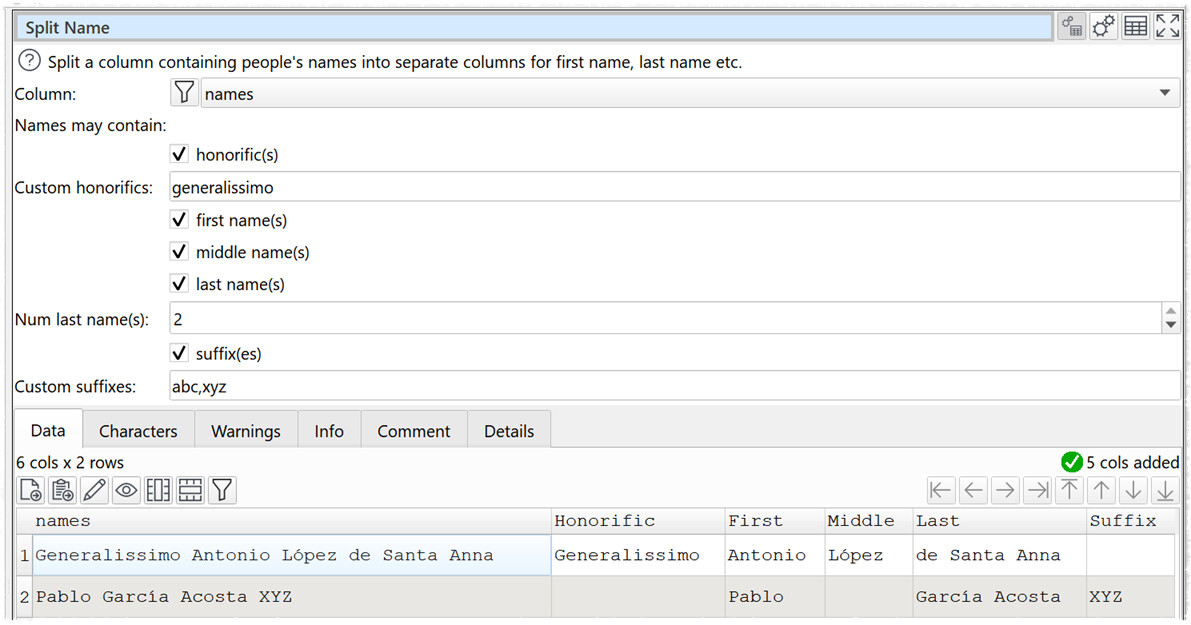
You can now specify custom honorifics and suffixes. You can also set whether 1 or 2 last names are expected.
That is probably as much as we are going to do on this transform (for this release anyway).
Hello,
To add to this already huge topic:
In Switzerland and Germany there is also the academic title Privat Docent/Privat Dozent, abbreviated as PD.
And in French any abbreviation ending with the last letter of the word has no punctuation:
e.g: Docteur → Dr, Professeur → Pr, Monsieur → Mr, Madame → Mme (plural Mmes).
As it was already said, it would be grand to be able to store in a variable custom/language specific terms.
Also - Feature request #wishlist
It would be great to be able to store variables (which may include code/Regex) to reuse in different transforms.
I have a collection of snippets of code for repeated use that I copy over whenever needed
The format for the variable interface could be:
Name|Content|Comment
Only the content would be pasted.
And to push the envelope the variables could be sorted by the user in subfolders such as:
Regex
Javascript
Abbreviations
…
Custom values for honorific and suffix have just been added.
That is somewhere on the wishlist.
If it is not too late, I had few more ideas about how to make Split Name more robust.
You could provide for each First, Middle and Last an option as counter to indicate what to expect in each part of the name.
| Options | Values |
|---|---|
| honorific(s) | Mr, Mrs, Miss, Dr, Sir |
| first name(s) | 2 count |
| middle name(s) | 1 count |
| last names(s) | 2 count |
| suffix(es) | PhD, Jr., CPA |
It could be a spinner or just an text input in front of each name part. This way you will have knowledge how to consume after splitting name and how many words to expect for each part.
| Names |
|---|
| Mr. John Paul Alexander Smith Jr. |
| Mrs. Yuki Haru Emi Tanaka |
As it always goes Honorific → First → Middle → Last → Suffix
Honorific
This is always a special case and if the first word is not in the honorific list it will be null otherwise it will take the first word. In this case it will take Mr.
First
It is set to two, so the next two words are taken John Paul
Middle
It is set to one, so it will take the next one word Alexander
Last
It is set to two and this is also a special case and if there are few or exact or more words (which is set for last) left, then last word is checked and if it is in Suffix list, it is ignored and if it is not then Last will take all remaining words, so in this case it will take Smith and ignore Jr.
Suffix
This is always special case as well and only the last word is checked and if it is in Suffix list then it is taken otherwise set to null. In this example it will take Jr.
Forgot to mention and hence edit, that Honorific and Suffix are always checked first and if the first word and last word are found in their respective position, then they are assigned and taken off from the word list.
The rest of the words are consumed from left to right as per their setting.
@Anonymous I think it makes sense to set the number of last names, as that tends to be reasonably consistent within cultures. I don’t know you can say the same for first and middle names. Also we really need to move on to other things.
Updated snapshot release:
Windows installer: https://www.easydatatransform.com/downloads/EasyDataTransform_2_6_1_snapshot_2.exe
Windows zip: https://www.easydatatransform.com/downloads/EasyDataTransform_Windows_2_6_1_snapshot_2.zip
Mac DMG: https://www.easydatatransform.com/downloads/EasyDataTransform_2_6_1_snapshot_2.dmg
Name splitters in the past have typically used lookup tables to test their values against. A last Name table might contain some variations such as “de la Cruz”, “van der Meer” etc. These were modifiable as new or unexpected values appeared in the data. By selecting and marking the obvious parts of the full name - Prefix (honorific), Suffix, etc. - the remaining data became more simplified for the remaining part of the transformation. Just a thought…
Another thought. With tables, it would be possible to have interchangeable tables for different name universes and nationalities when needed. A user could also create his/her own custom lexicons as well.
We have built in common particules, such as ‘de’, ‘la’, ‘van’, ‘der’, ‘von’ etc. We could possibly allow this list to be customized. However, I suspect 95%+ of users don’t know what a particule is.
In the latest version, you can supply your own list of honorifics and suffixes.
The new Split Name transform is now available in v2.7.0.
I often have lists of names where there are entries such as “John and Jane Doe” or “John Smith and Jane Doe”. Does is make sense to treat and as a special word, so, for example, if it is after a first name, the First Name result becomes the first 3 words, such as “John and Jane” “Doe”?
I’m not sure what to suggest when and connects two full names, perhaps an option to make two rows from it. Not sure about that one!
I’ve had a conversation offline with @OttoDaFe about handling multiple guests per line. The current Split Name transform doesn’t handle this.
It is complicated because there are so many different forms multiple names can take. For example:
Mr & Mrs John Doe
Mr John and Ms Jane Doe
Mr John Smith + Ms Jane Doe
John Smith & Jane Doe
John and Jane Smith
And that is without allowing for:
- the equivalent of ‘and’ in other languages
- more than 2 names per row
- suffixes and middle names
I came up with a .transform, which handles all the above example cases, apart from the first (rather sexist!) one. I could have handled that case as well if there was the ability to Slide on key value (as there is for Fill). Something which is on the wishlist.

multiple-names.transform (4.5 KB)
Perhaps you can tweak it to fit your particular case.
Thank you, that’s an interesting solution!
For simplicity, in my particular case I was thinking of just making the first name the entire string consisting of the word before and after the conjunction. In other words, Jane and John Doe becomes FN: Jane and John LN: Doe. But splitting into 2 records I also hinted about and in many cases that can be a better solution. I envisioned that the separators/conjunctions could be custom defined in the same way custom honorifics could be defined.
As you say, splitting names is an extraordinarily complex thing to do. I was quite tickled you managed to add that so effectively. As you point out, the result almost always will require some cleanup. While a simple tweak here and there can help I have no expectation that every case can be handled. That split name transform is awesome, no matter how you look at it.
I guess that is also a possibility. Is it useful to have ’ Jane and John’ as a first name? Also the conjuntion can come in different places, e.g. ‘Mr & Mrs John Smith’, ‘Mr John & Mrs Jane Smith’, ‘Mr John Smith & Mrs Jane Smith’. Even ‘Mr & Mrs John & Jane Smith’.
I have added an extra option to Slide so that you can now only slide up/down rows with the same key value (similar to you can already do with Fill). Which means you can now do this for the example data above:
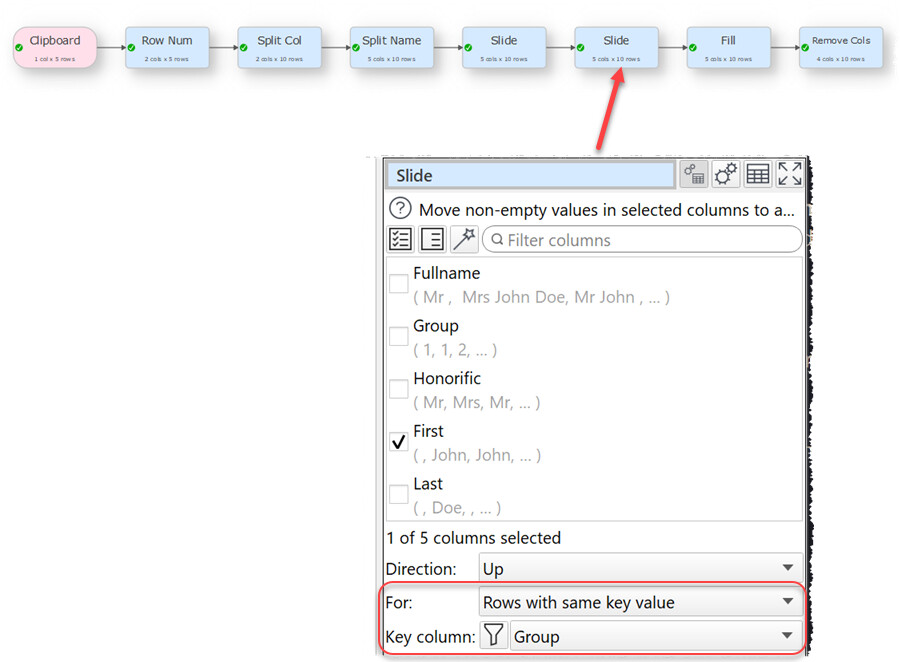
And end up with:
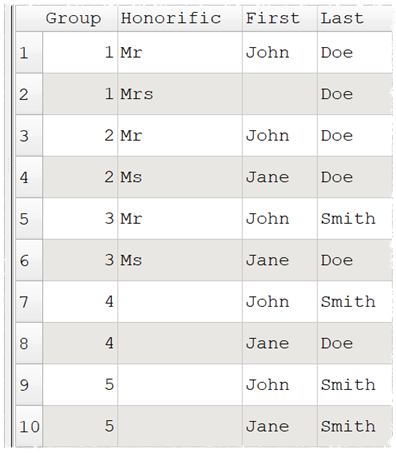
The Slide enhancement will be in the next release.
I suppose that depends upon the purpose of the data. Here are two examples where extra/partially duplicated rows would not be wanted: 1) you’re cleaning an address book (perhaps to send holiday cards) or 2) creating an online email discussion list. In those cases you’d want only one address label to be generated or an email address to be included only once.
Thanks as usual for your thorough responses.
1 Like